♰ Universitat Politecnica de Catalunya
✦ Massachusetts Institute of Technology
✥ Qatar Computing Research Institute
Abstract
In this work we train a neural network to learn a joint embedding of recipes and images that yields impressive results on an image-recipe retrieval task. Moreover, we demonstrate that regularization via the addition of a high-level classification objective both improves retrieval performance to rival that of humans and enables semantic vector arithmetic. We postulate that these embeddings will provide a basis for further exploration of the Recipe1M+ dataset and food and cooking in general. Code, data and models are publicly available.
Check out our most recent journal paper for full details and more analysis! Our CVPR paper can be downloaded from here.
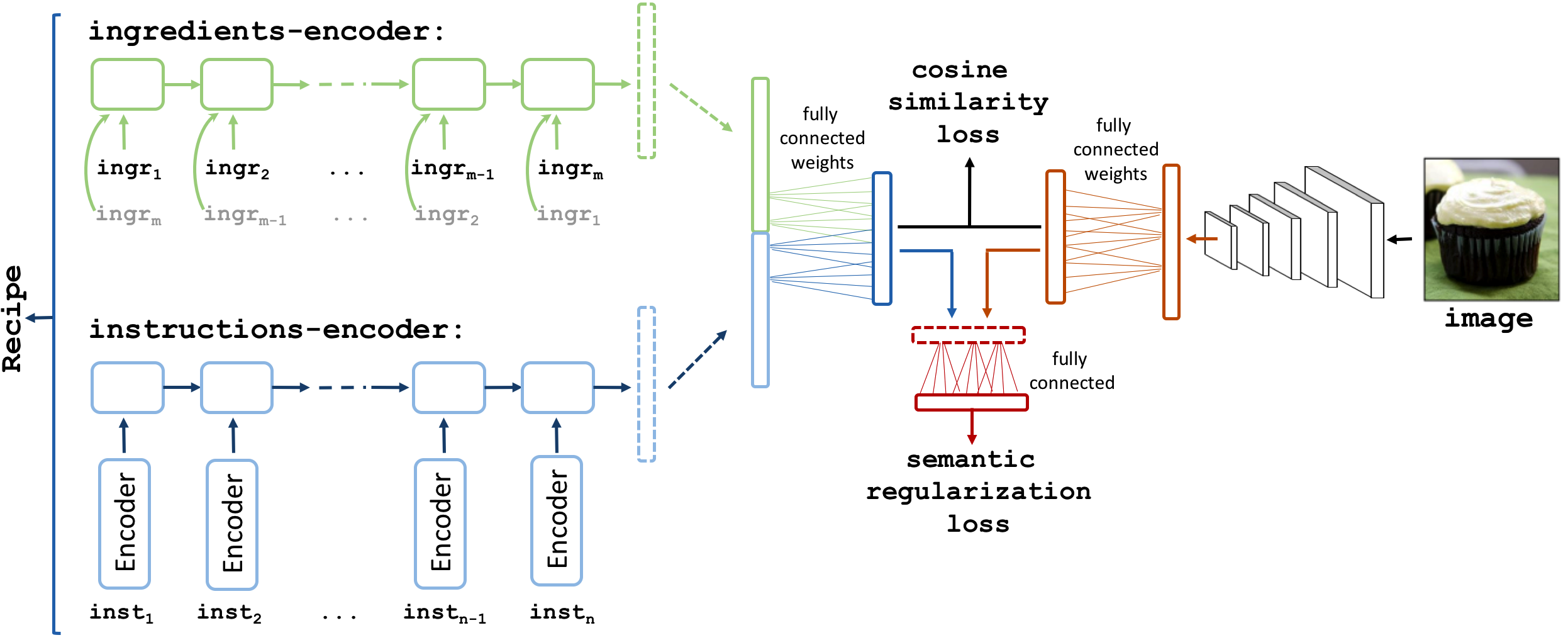
Joint embedding
We train a joint embedding composed of an encoder for each modality (ingredients, instructions and images).
Results
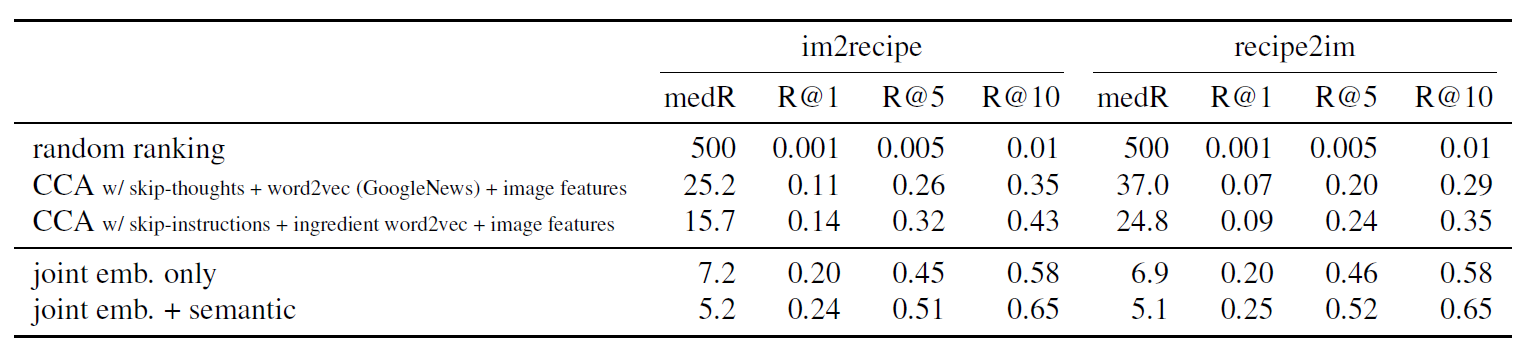
im2recipe retrieval
We evaluate all the recipe representations for im2recipe
retrieval. Given a food image, the task is to retrieve its recipe
from a collection of test recipes.
Comparison with humans
In order to better assess the quality of our embeddings we
also evaluate the performance of humans on the im2recipe
task.
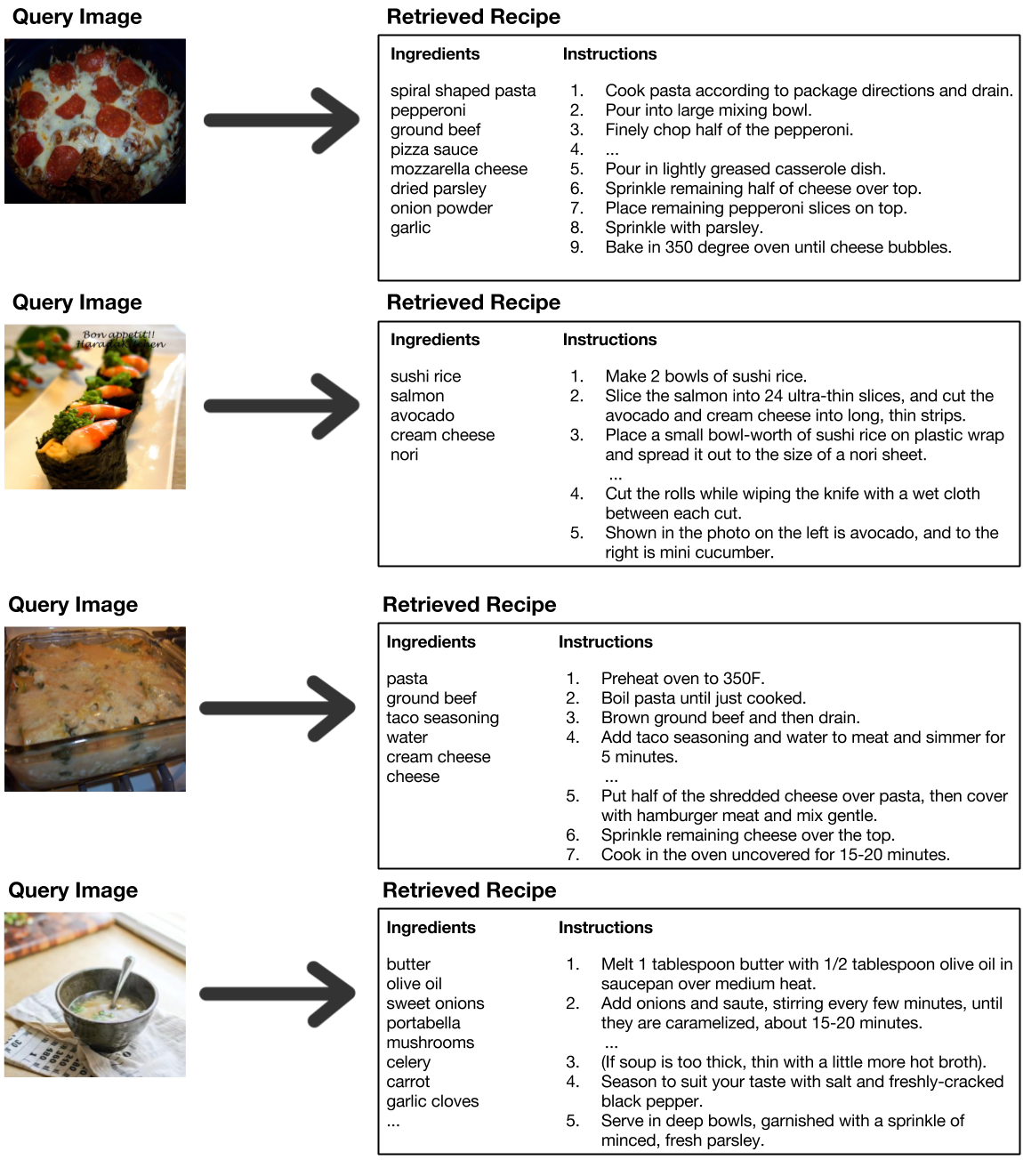
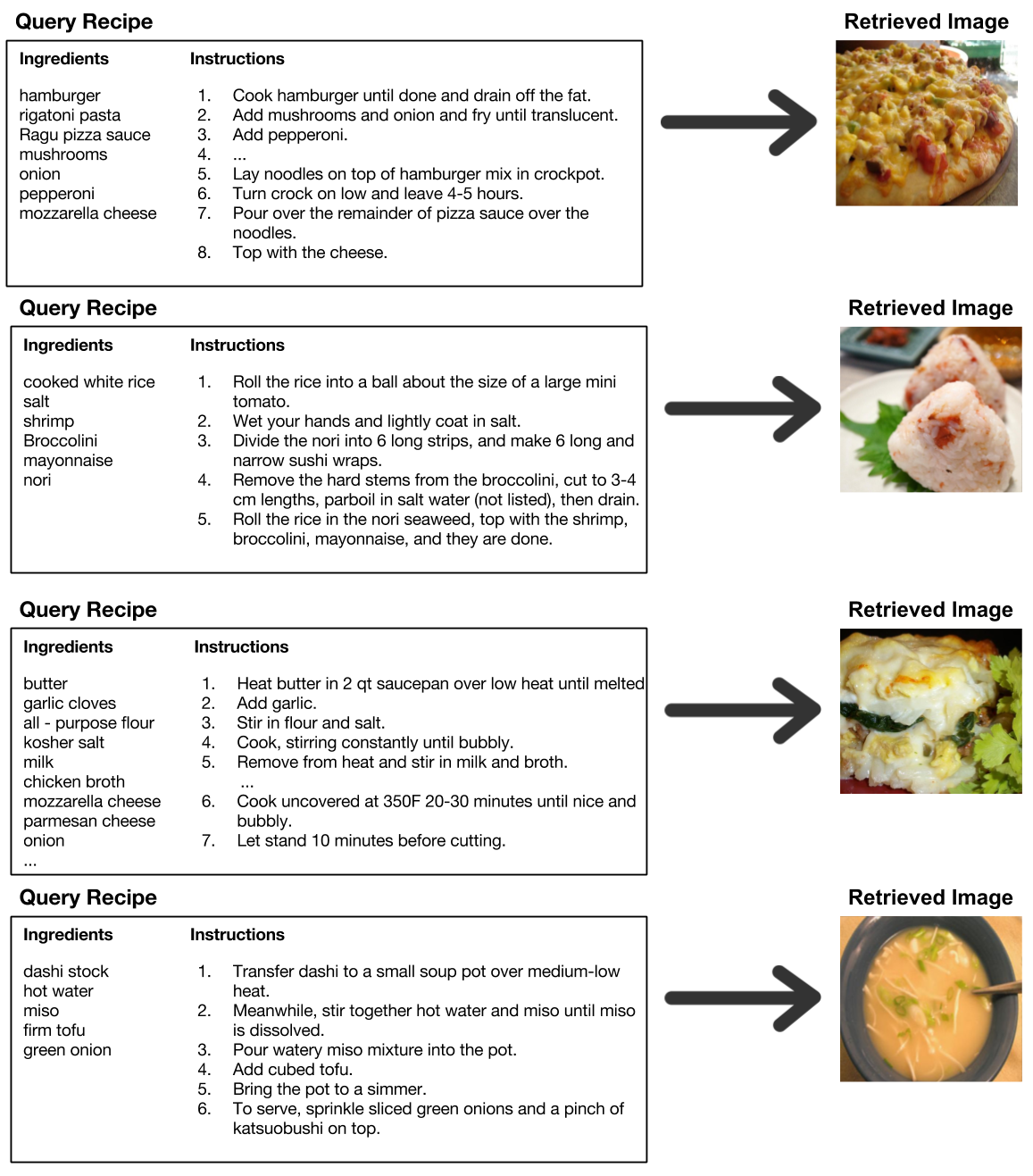
Examples
Embedding Analysis
We explore whether any semantic concepts emerge in the neuron
activations and whether the embedding space has certain
arithmetic properties.
Visualizing embedding units
We show the localized unit activations in both image and recipe embeddings. We find that
certain units show localized semantic alignment between
the embeddings of the two modalities.
Arithmetics
We demonstrate the capabilities of our learned embeddings with simple arithmetic
operations. In the context of food recipes, one would expect that:
v(chicken\_pizza) - v(pizza) + v(lasagna) = v(chicken\_lasagna)
where v represents the map into the embedding
space.
We investigate whether our learned embeddings have
such properties by applying the previous equation template
to the averaged vectors of recipes that contain the queried
words in their title. The figures below show some results with same and cross-modality embedding arithmetics.
| Image Embeddings |
Recipe Embeddings |
 |
 |
Fractional arithmetics
Another type of arithmetic we examine is fractional arithmetic, in which our model interpolates across the vector representations of two concepts in the embedding space. Specifically, we examine the results for:
 + (1-x) \times v(\text{'concept 2'}),)
where 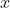 varies from 0 to 1.
varies from 0 to 1.
| Image Embeddings |
Recipe Embeddings |
 |
 |
Embedding visualization
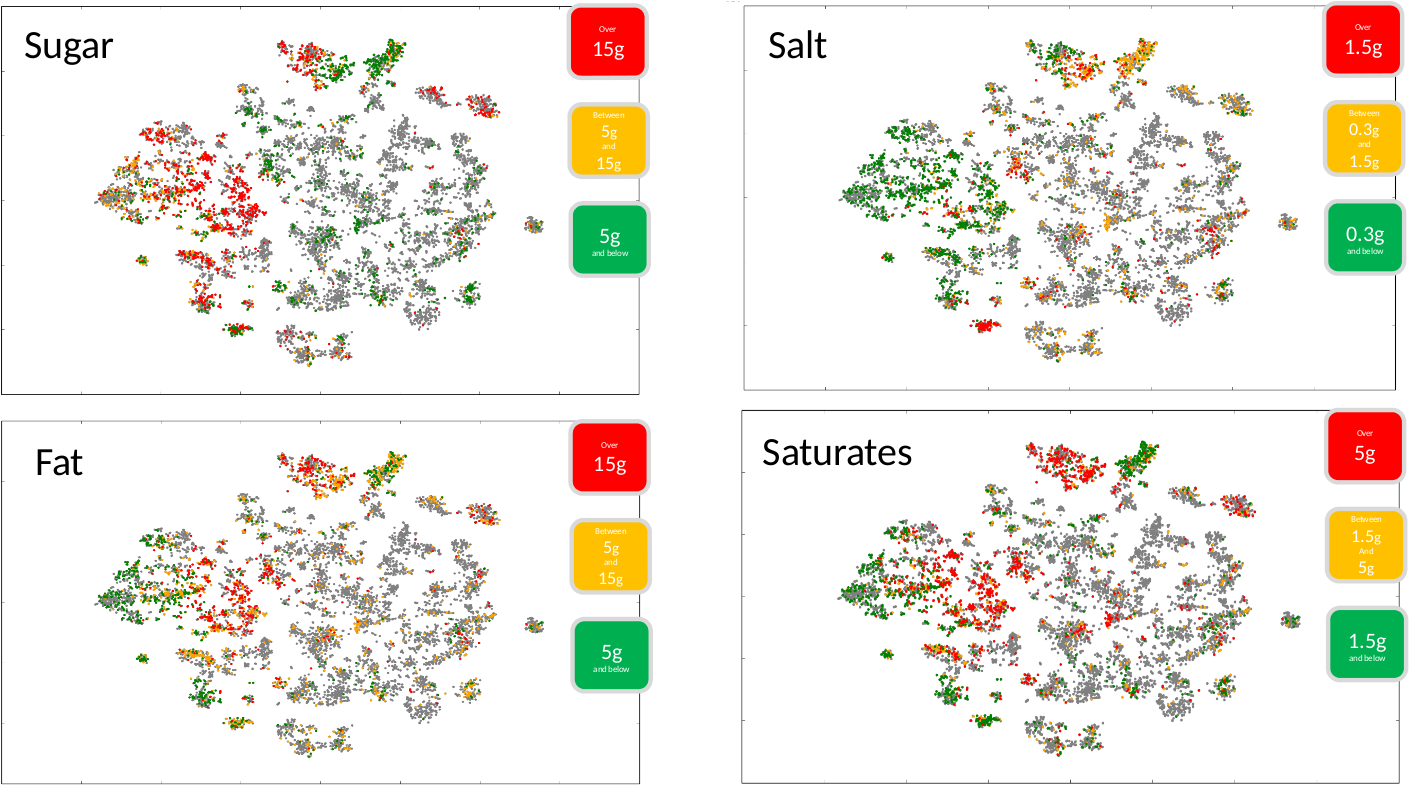
In order to visualize the learned embedding we make use of t-SNE and the 50k recipes with nutritional information we have within Recipe1M+.
Semantic categories
In the figure bellow we show those recipes that belong to the top 12 semantic categories used in our
semantic regularization.
Healthiness within the embedding
In the next figure we can see the previous embedding visualization but this time showing the same recipes on different
colors depending on how healthy they are in terms of sugar, fat, saturates and salt.
Citation
@article{marin2019learning,
title = {Recipe1M+: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images},
author = {Marin, Javier and Biswas, Aritro and Ofli, Ferda and Hynes, Nicholas and
Salvador, Amaia and Aytar, Yusuf and Weber, Ingmar and Torralba, Antonio},
journal = {{IEEE} Trans. Pattern Anal. Mach. Intell.},
year = {2019}
}
@inproceedings{salvador2017learning,
title={Learning Cross-modal Embeddings for Cooking Recipes and Food Images},
author={Salvador, Amaia and Hynes, Nicholas and Aytar, Yusuf and Marin, Javier and
Ofli, Ferda and Weber, Ingmar and Torralba, Antonio},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
Acknowledgements
This work has been supported by CSAIL-QCRI collaboration projects and the framework of projects TEC2013-43935-R and TEC2016-75976-R, financed by the Spanish Ministerio de Economia y Competitividad and the European Regional Development Fund (ERDF).